Capability-based OS
Extension of the capability-based operating system - Barrelfish OS.
Modern hardware features pose various challenges for designing and implementing modern operating systems, in the course “Advanced Operating System” 263-3800-00L we explored different aspects of operating system development. This was a course I took during my final semester FS2024 of undergraduate studies at ETH Zürich, and it was entirely graded based on practical implementation work in C and assembly language and a final project report.
In my opinion, this course was incredibly interesting. Having a good understanding of the book “Computer Systems: A Programmer’s Perspective” by Bryant and O’Hallaron should suffice to provide you a good start.
Roadmap for Building the Essence of an OS
In monolithic kernels, like Linux, the kernel handles the virtual and physical memory.
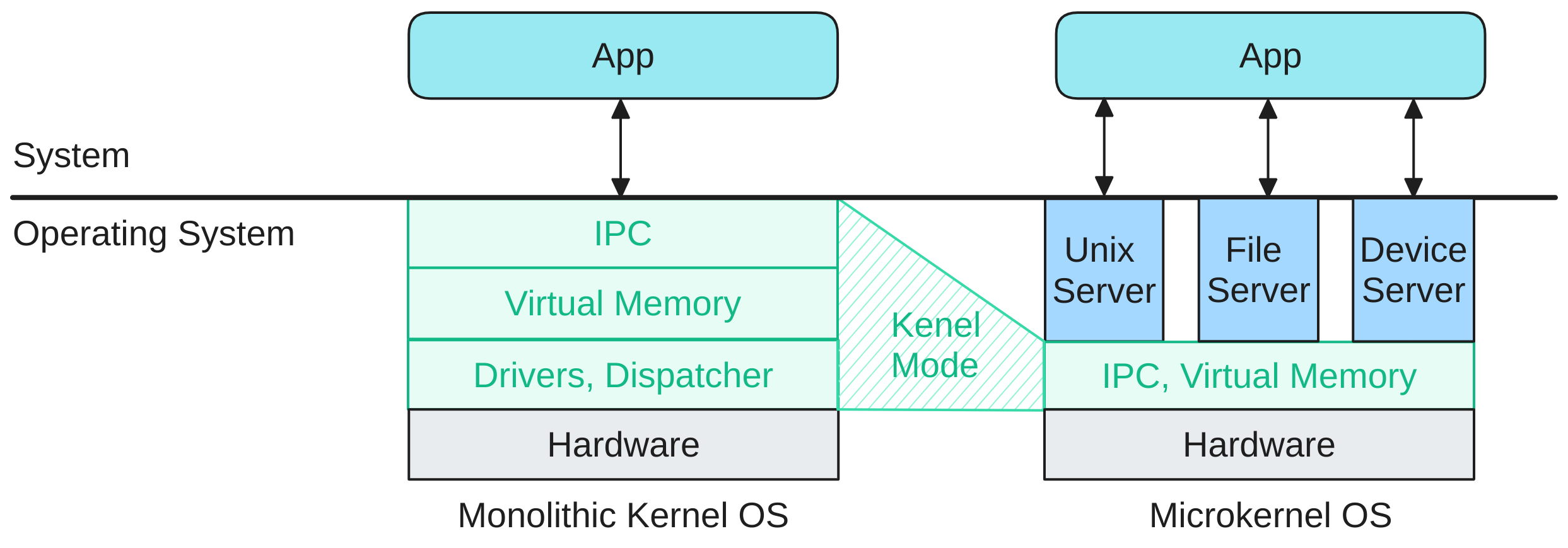
In Barrelfish, memory management is moved from the kernel to the user space. This means that processes handle their own virtual address space and page faults triggered by themselves. In order to ensure correct access control, Barrelfish uses capabilities to track resources and guarantee only allowed access. A capability refers to, in the case of memory management, a specific area of memory and allows the holder of it to manipulate the region of memory described by it. We begin our journey by implementing a memory manager responsible for distributing random access memory (RAM) to the initial process. It needs to track what is free and what is allocated in the physical address space, while performing the necessary capability operations.
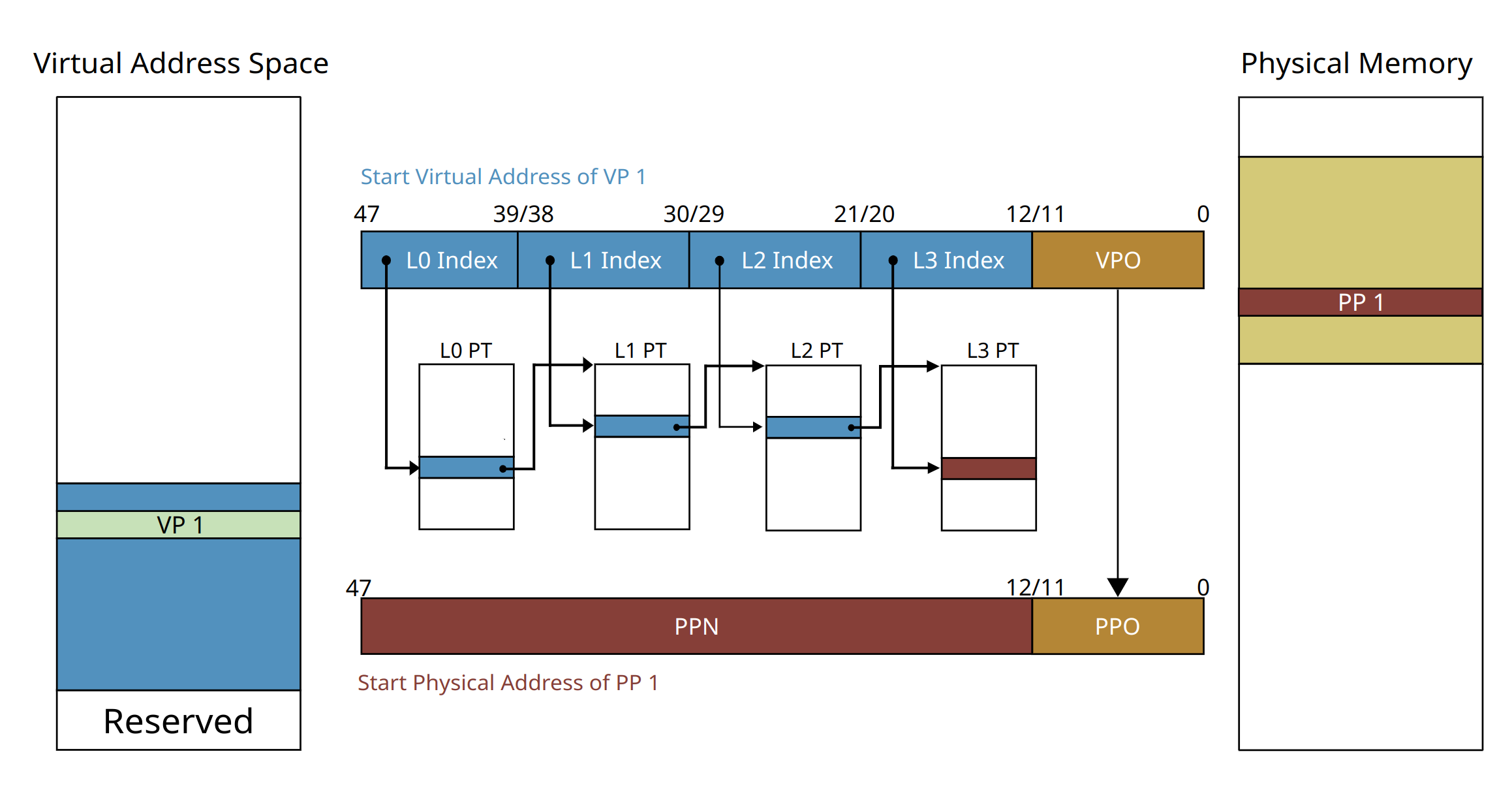
For the management of the virtual memory and page fault handling in user space, we back up all the memory mappings during the address translation with a multi-level page table, and additionally, we implement a resource manager to keep track of the memory usage of the virtual address space.
Next, the focus shifts to spawning new processes. This involves initializing new processes, registering them with the Barrelfish CPU driver, and implementing a process manager. The process manager acts as a server process to manage and manipulate these newly spawned processes.
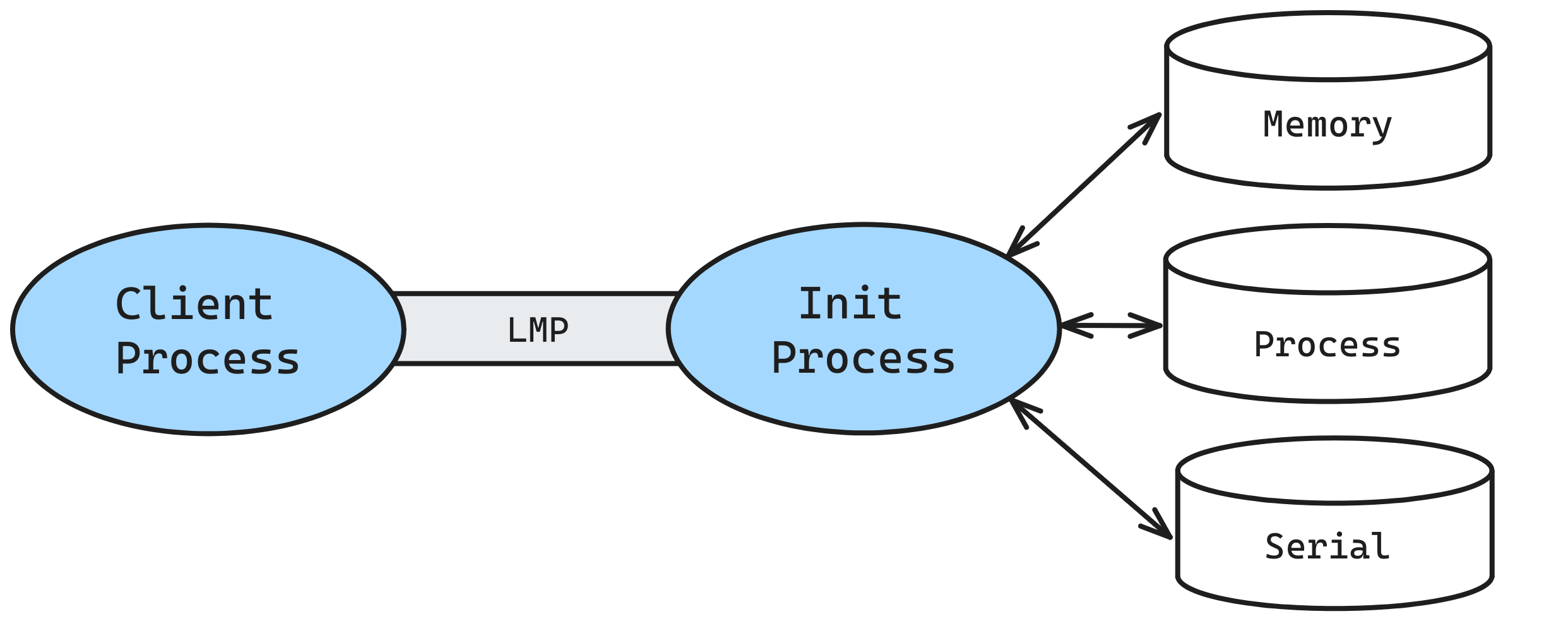
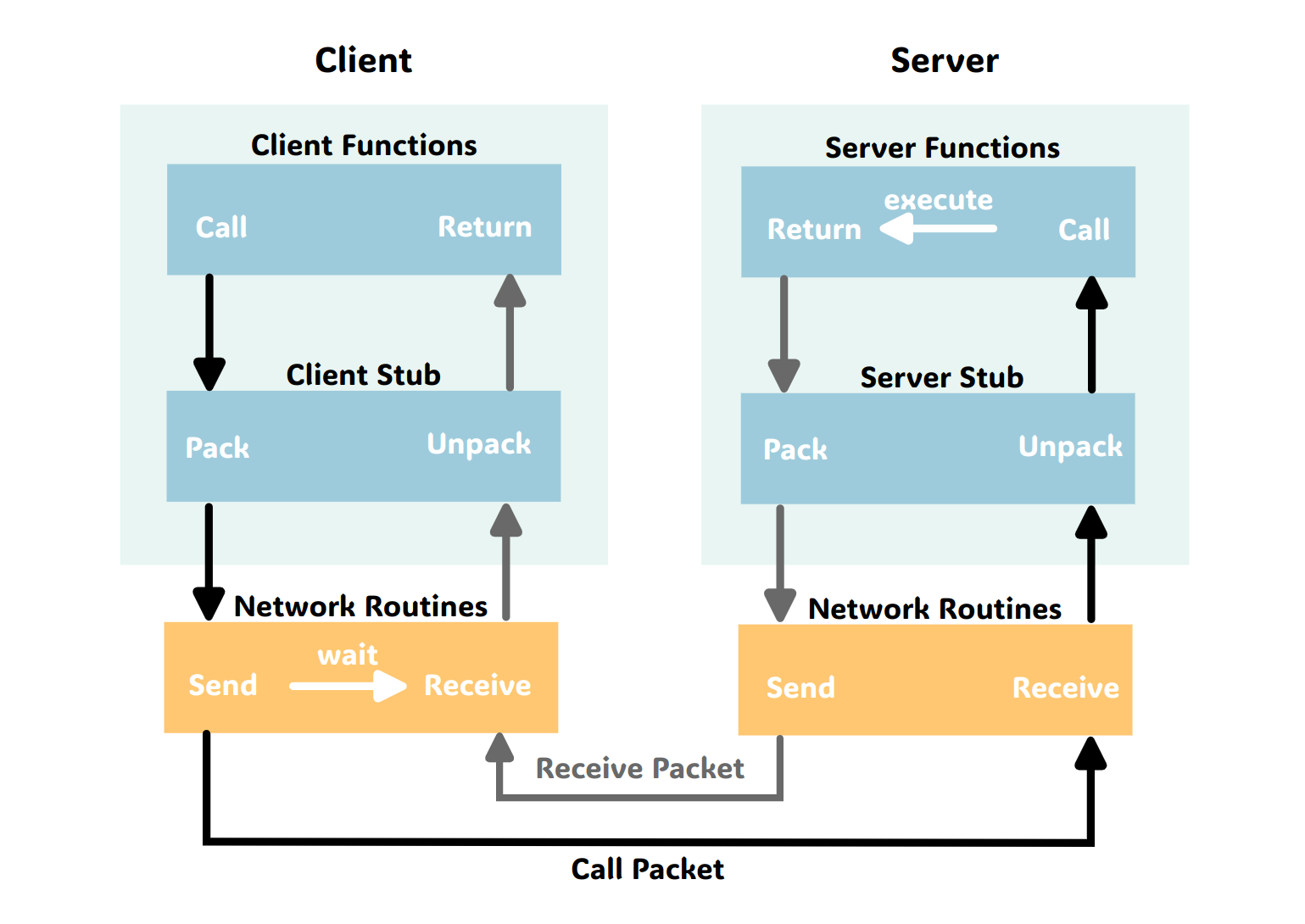
As multiple processes run simultaneously, facilitating communication between them becomes essential. A protocol is designed using existing kernel infrastructure to establish channels for lightweight message-passing (LMP) between processes.
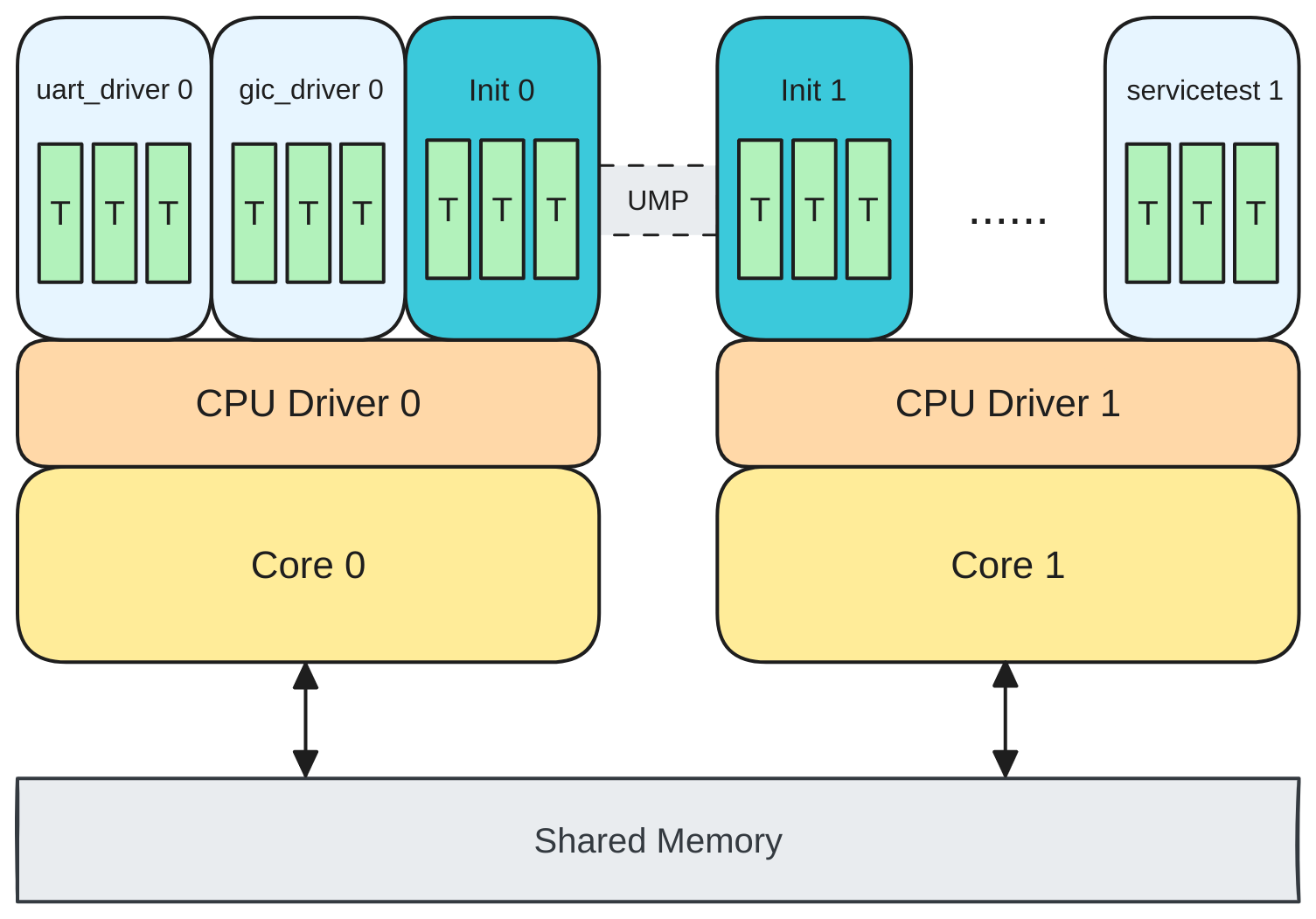
Up until this point, the system ran on a single core. While threads can create the illusion of concurrency, true parallelism requires utilizing multiple cores. To enable multicore usage on the Toradex board used in this project, we boot a second core, establish communication between bootstrap core and it, and allocate RAM resources to processes in this new multicore environment.
Finally, the communication system is refined and unified with user-level message passing (UMP) for inter-core communication.
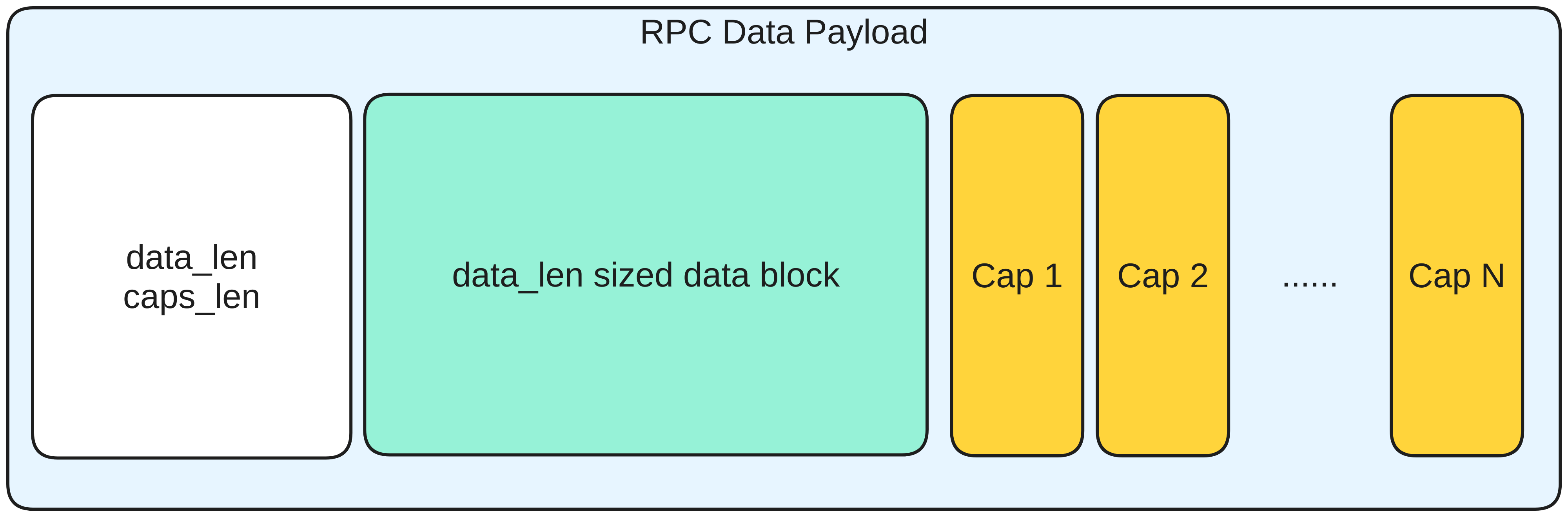
We also refined our previous design and provide a more generic and versatile RPC interface for our multicore system in which we design a new data payload format, allowing our RPC user interface to be communication-protocol-agnostic from the user’s perspective. We also ensured our design is thread-safe, having the concurrency issues in mind.
Providing Distributed Nameservice
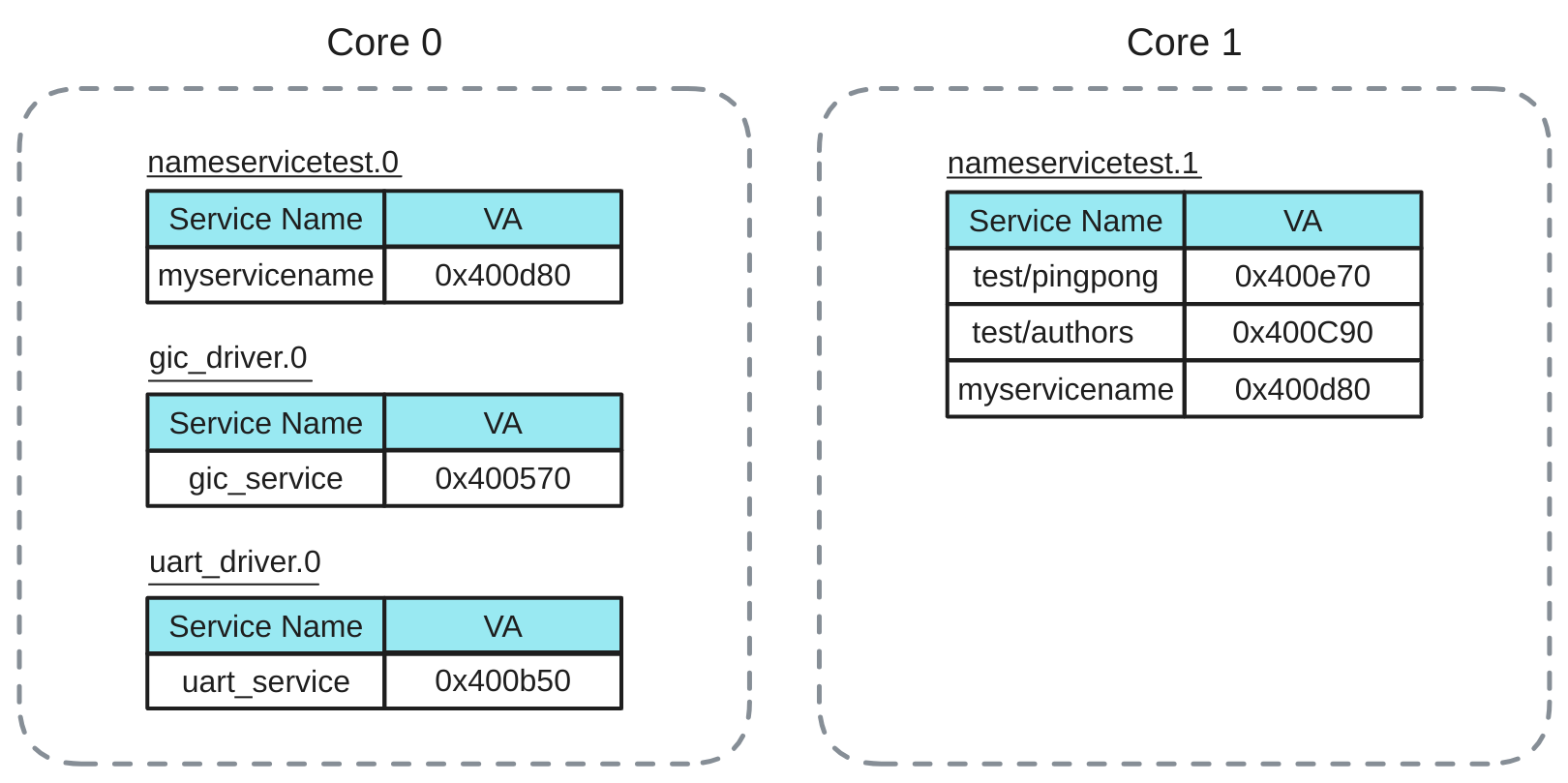
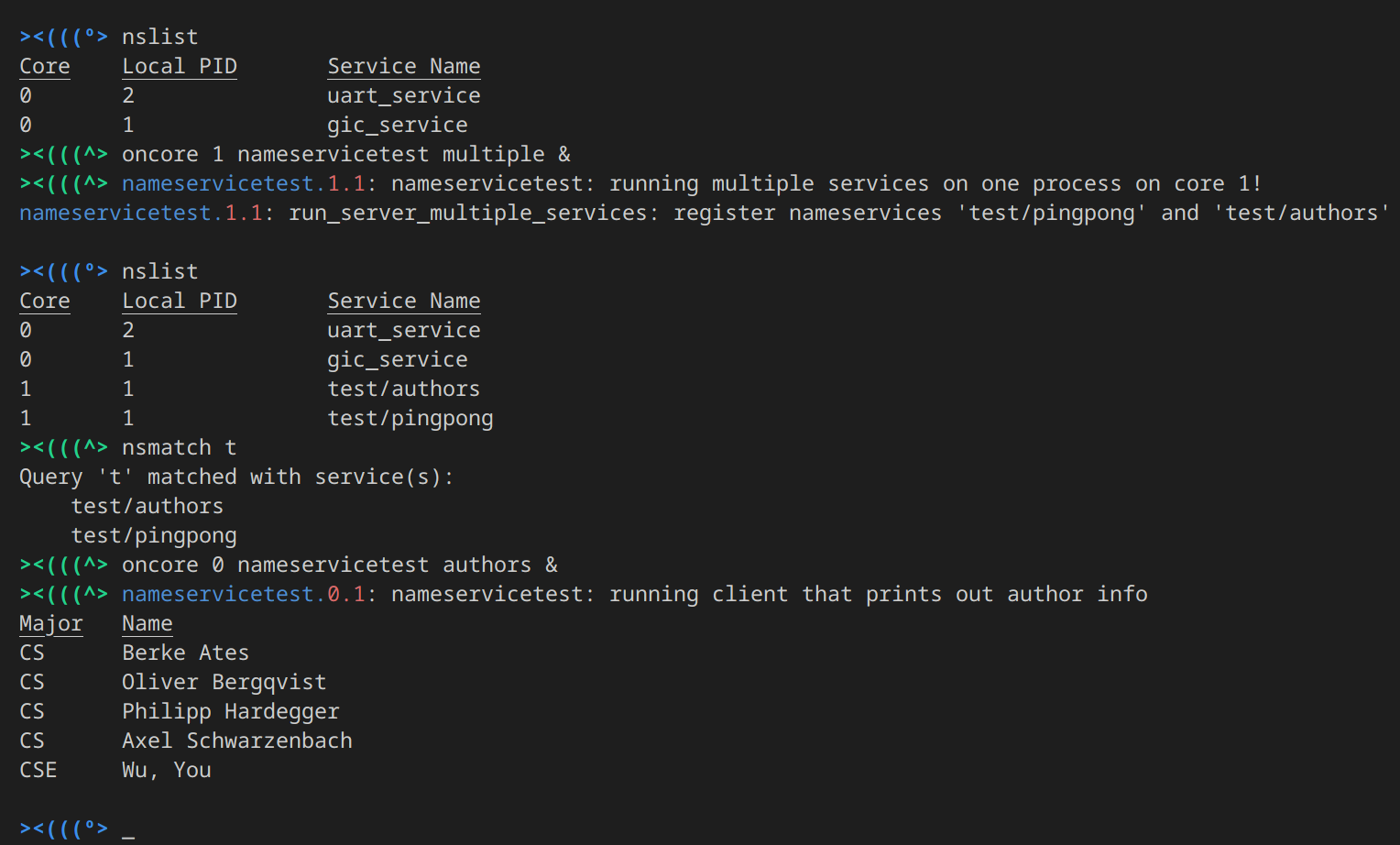
Building on the group work described above, the course concludes with an individual project where I was responsible for implementing the nameservice. This involved developing distributed nameservers in our multicore system, allowing server processes to register multiple services and enabling client processes to efficiently look up and establish communication channels.
The main task of a nameserver is to maintain a nameserver-side lookup table (LUT) for the key-value lookup. Every value pair contains a name that should convey certain naming convention, and an opaque pointer to the server handle for the registered name. The server handle is used to refer back to the server process that provides the particular service, and it should comply with the server handle of the RPC interface for consistency.
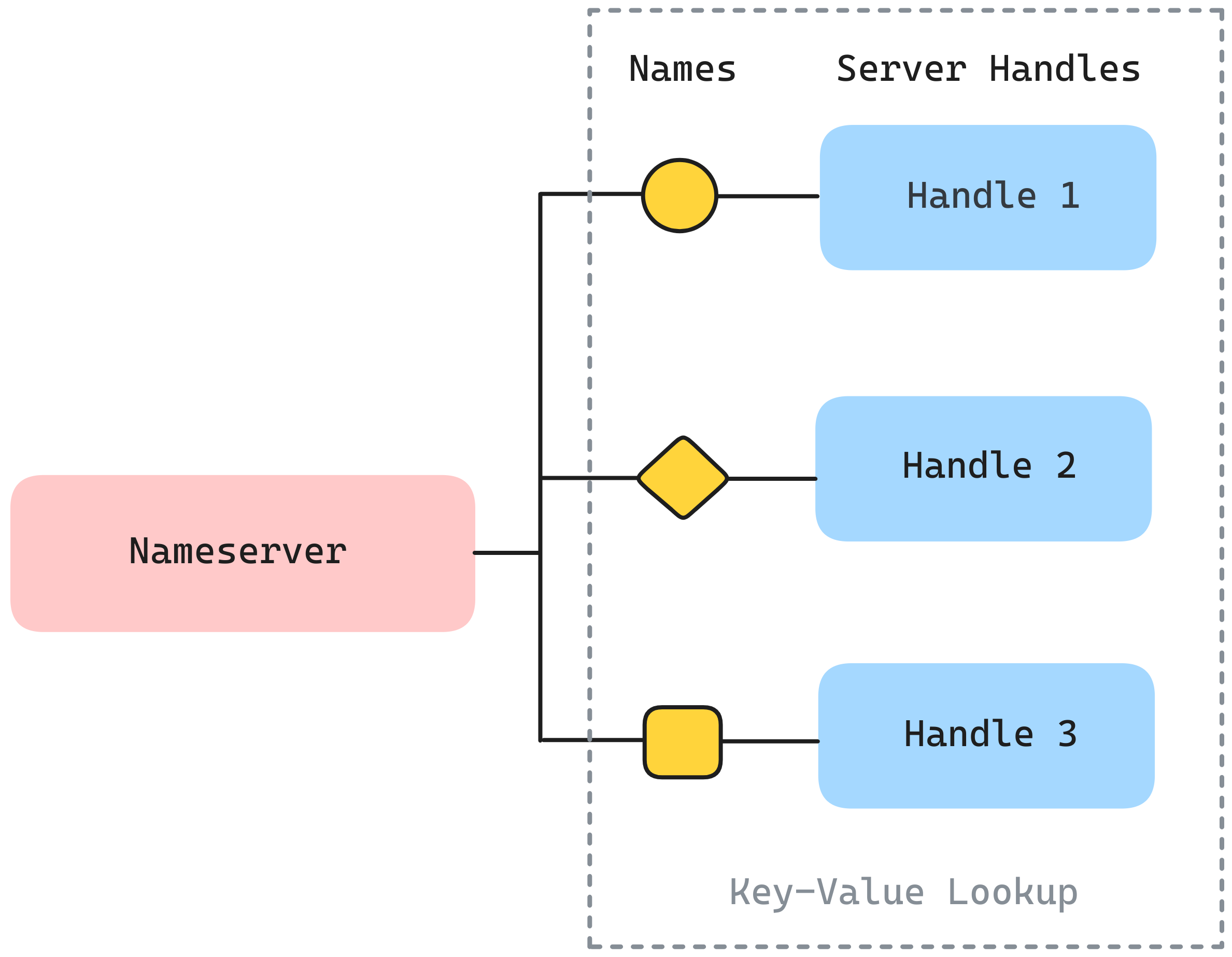
There is also a server-side LUT, which is distinct from the nameserver-side LUT. A server process possesses a server-side LUT that is used for the lookup of the pointer to the server handler function, given a service name. The idea of maintaining a server-side LUT meets the need to enable a single process to provide multiple services.
As an outcome, we were able to request various different services across cores and we also integrated this functionality into our shell, providing convenient commands for requesting and listing available services.
References
2009
-
 The multikernel: a new OS architecture for scalable multicore systemsIn Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, 2009
The multikernel: a new OS architecture for scalable multicore systemsIn Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, 2009